RAG 是什么?
by Canonical on 11 April 2025
在 2020 年的一篇论文中,Patrick Lewis 和他的研究团队引入了术语 RAG,即检索增强一代。该技术通过利用外部知识来源,如文件和广泛的数据库,增强了生成式 AI 模型。RAG 填补了传统大型语言模型(LLM)中的一个空白。传统的模型依赖于已经包含在其中的静态知识,而 RAG 则结合了最新信息,作为 LLM 的可靠事实来源。虽然 LLM 可以在没有 RAG 的情况下快速理解和响应提示,但它们通常不能提供最新或更具体的信息。
RAG 的一个实际应用是对话代理和聊天机器人。借助 RAG 模型,这些系统能够从外部来源获取上下文相关的信息,从而增强自身性能。这种能力确保客户服务聊天机器人、虚拟助理和其他对话界面在交互过程中提供准确和信息丰富的响应。另一个用例是在高级问答系统中,RAG 模型可帮助个人获得查询的答案,例如支持票证响应。此外,RAG 可用于内容推荐系统,通过检索相关信息提供个性化推荐,以增强用户体验和内容参与度。
使用 RAG 的好处
构建信任的数据源
将机器学习模型用于企业应用程序(例如聊天机器人)或搜索敏感数据时,RAG 为模型提供可引用的可验证信息。该方法使模型能够专注于不太模糊的背景信息,大大降低了产生错误输出的可能性,这种现象通常被称为“幻象”。
最新信息
使用 RAG,您可以加载最新的可靠数据,确保您的模型将检索到准确的信息。
RAG 的简单性
Lewis 和三位合著者发表了一篇题为《知识密集型 NLP 任务的检索增强生成》的论文,其中他们只用五行代码演示了 RAG。该实施生成了一个模型,包括一个问题编码器、一个检索器和一个生成器,用于生成上下文感知的答案。该实施的简单性表明,RAG 作为一个概念和项目相对容易操作。然而,在生产和大规模部署中,复杂性确实增加了。
降低持续模型重新训练的成本
持续重新训练机器学习模型可能会很昂贵。利用 RAG,不需要依赖于时间密集和昂贵的参数重新训练。这可能降低在企业环境中运行 LLM 驱动的聊天机器人的计算和财务成本。
RAG 的工作原理
当在 AI 聊天机器人中进行查询时,基于 RAG 的系统首先从大型数据集或知识库中检索相关信息,然后这些信息用于通知并指导生成回复。基于 RAG 的系统由两个关键组件组成。第一个组件是检索器,它负责定位有助于回答用户查询的相关信息。它搜索数据库以选择最相关的信息。然后,将该信息提供给第二个组件,即生成器。生成器是一个产生最终输出的大型语言模型。见下图:
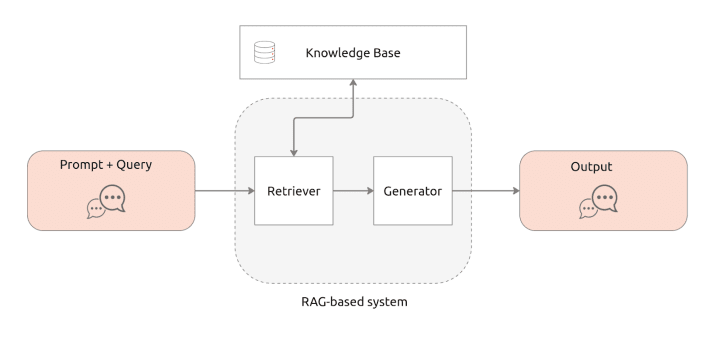
在使用基于 RAG 的系统之前,必须首先创建知识库,它由未包含在 LLM 训练数据中的外部数据组成。这些外部数据可能来自不同的来源,包括文档、数据库和 API 调用。大多数 RAG 系统利用一种称为模型嵌入式 AI 技术,将数据转换为数字表示,并将其存储在矢量数据库中。使用嵌入式模型,您可以创建一个在 AI 环境中易于理解和检索的知识模型。在创建知识库并设置矢量数据库后,现在可以执行 RAG 过程;以下是一个概念性流程:

基于 RAG 的系统包含五个简单的步骤:
- 您可以通过输入提示或查询来开始操作。
- 检索器用于从知识库中搜索相关信息。通过矢量搜索和数据库功能,可以使用数学矢量计算和表示来确定相关性。
- 检索相关信息来提供增强的上下文,并将其传递给生成器。
- 现在使用这些上下文来丰富查询和提示,并准备好使用提示工程技术 (LLM)来扩充,以用于大型语言模型。增强的提示使语言模型能够准确地响应您的查询。
- 最后,向您发送生成的文本响应。
Canonical 满足您的 RAG 要求
使用 Canonical RAG workshop 构建正确的 RAG 架构
Canonical 提供为期 5 天的 workshop,旨在帮助您开始构建自己的企业 RAG 系统。在 workshop 结束时,您将对 RAG 和 LLM 理论、架构和最佳实践有一个透彻的理解。我们将共同开发和部署满足您特定需求的解决方案。
下载数据表
了解更多信息并联系我们的团队,以满足您的 RAG 需求。
订阅博客文章
查看更多内容
利用开源机器学习基础架构加速 AI 发展
人工智能技术在迅速发展,对稳健强大且可扩展的基础架构具有迫切需求。为应对这些挑战,我们精心打造了一套全面的参考架构(RA),充分利用了开源工具与尖端硬件的强大功能与性能。这套架构基于 Canonical 的 MicroK8s 和 Charmed Kubeflow 构建,运行于 Dell PowerEdge R7525 服务器之上,并借助NVIDIA NIM 微服务实现加速,为部署和管理机器学习工作负载提供了一个简便高效的途径。 为数据科学家与工程师赋能 该解决方案旨在为数据科学家和机器学习工程师赋能,使其能够实现更快迭代、无缝扩展以及强有力的安全保障。对于基础架构构建者、解决方案架构师、DevOps 工程师以及首席技术官(CTO)而言,这套参考架构提供了一条畅通无阻的途径 […]
Ubuntu 正式支持 NVIDIA Jetson
Ubuntu 正式支持 NVIDIA Jetson:助力边缘 AI 未来发展 Canonical 宣布推出支持 NVIDIA® Jetson Orin™ 的 Ubuntu 正式发布版本,该版本专为边缘 AI 和机器人领域打造,为全球 AI 开发者带来优化的性能、开箱即用的兼容性以及实现高性能 AI 解决方案的便捷途径。 Ubuntu 发行商 Canonical 宣布正式支持 NVIDIA Jetson 平台,标志着其与 NVIDIA 的合作迎来重要里程碑,为加速边缘 AI 领域创新再添动力。此次正式发布(GA)版本为 Ubuntu 与 NVIDIA Jetson 系统级模块解决方案的强大组合赋予了企业级的稳定性与技术支持。 为各行各业 AI 创新赋能 此次通过 Canon […]
NIS2 合规指南:第 2 部 — 了解 NIS2 合规要求
在上一篇博客文章中,笔者详细介绍了 NIS2 及其适用对象。本系列的第二篇文章中将详细介绍 NIS2 中的主要要求,并将这些要求具体转化为切实可行的行动措施,助力企业组织满足 NIS2 合规要求。欢迎阅读本文,一同深入了解 NIS2 的内容。 NIS2 适用于您。那么,您需要做些什么来满足 NIS2 合规要求? 如果您正在阅读本文,想必已经意识到 EU NIS2 适用于您所在的公司。接下来,让我们深入探究其中的具体要求,以及为实现合规性需要采取的行动。 该指令规定,相关实体必须落实网络安全风险管理措施,且这些措施必须“适当适度”。尽管这一要求看似宽泛,存在一定的解释空间,但指令中明确规定了一系列必须落实的最低限度的网络安全风险管理措施。 下面将细入探讨这些措施,并将其转化 […]